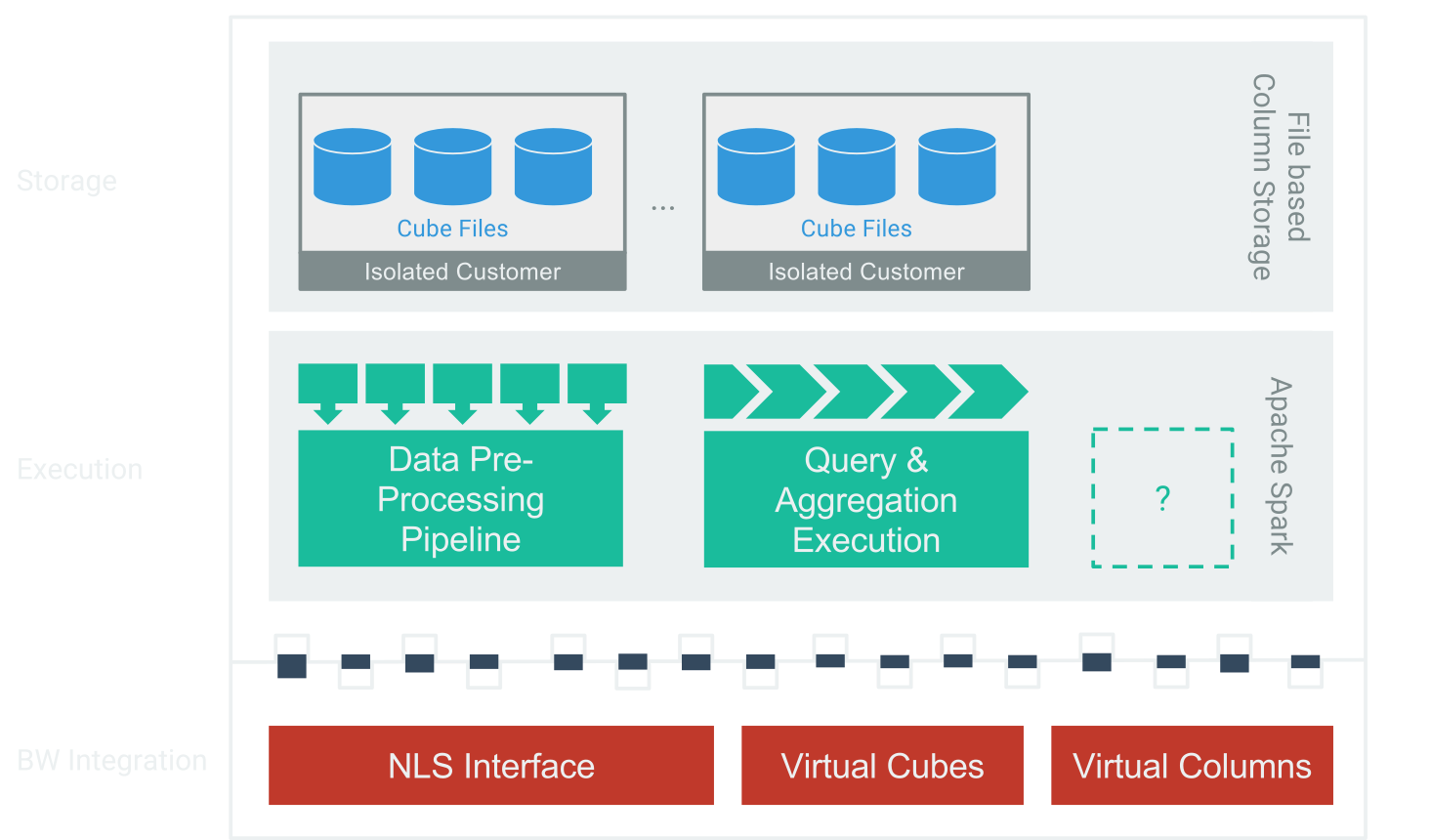
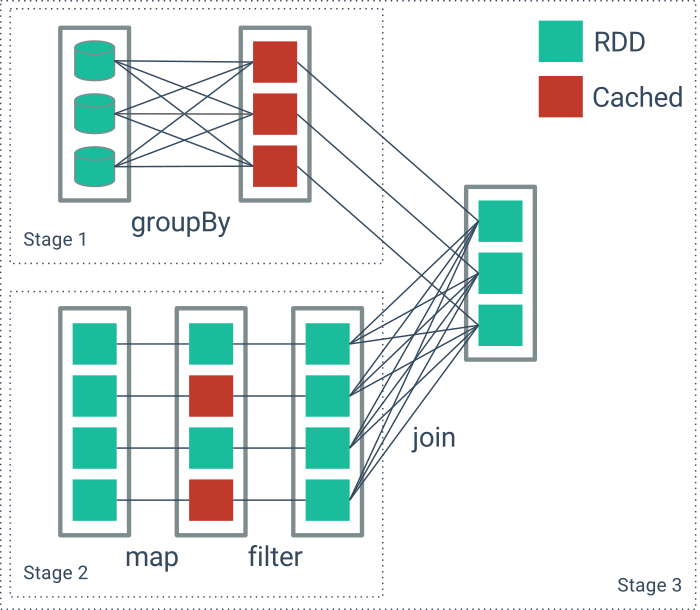
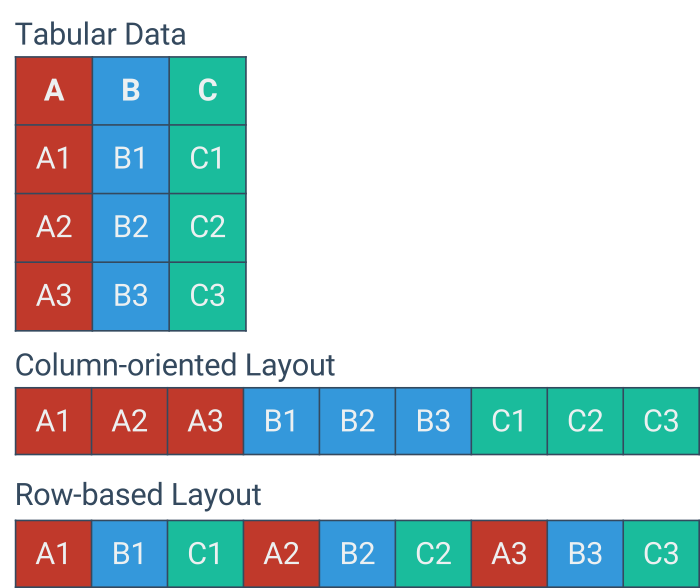
SparrowBI provides in-memory performance for the price of an data archival solution.. A deep integration into SAP-BW using standard interfaces avoids re-development or introduction of new technology. Die execution layer leverages modern, massiv parallel in-memory technology based on Apache Spark. Due to hosted operation SparrowBI scales on demand. SparrowBI relies for storage on file-based columnar databases, which are persisted in a performant and redundant IO-architecture. Thereby SparrowBI provides enterprise-ready data-security and governance to safely store and report company data.